TSQA阅读笔记
文章基本信息
Paper:TSQA: Tabular Scenario Based Question Answering【AAAI 2021】
研究背景与进展
在人机交互/问答领域,基于场景的问答(SQA)作为新兴的问答任务,对比传统的机器阅读理解(MRC)任务,更加具有挑战性。本文对SQA的分支基于表格场景的问答(TSQA)进行了研究。目前传统的机器阅读理解(MRC)方法仅能通过阅读文本段落来提取或推断答案,而TSQA任务中提供的表格数据不能被其直接捕获,需要通过自然语言手动解释。本文注重于在这样的场景下,提供一个全自动的方式来解决TSQA问题。
研究思路及逻辑
任务定义
TSQA任务由场景<P,T>,问题Q,一系列候选答案O组成。而场景由一段文字P以及一组表格T组成。我们的目标是从O中选定一个选项作为以<P,T>为背景的问题Q的答案。
由定义可知,该任务需要通过阅读文字P以及解析表格T中蕴含的信息才能够较好地完成。对于这样的问题,文中提出的解决思路如下图所示:
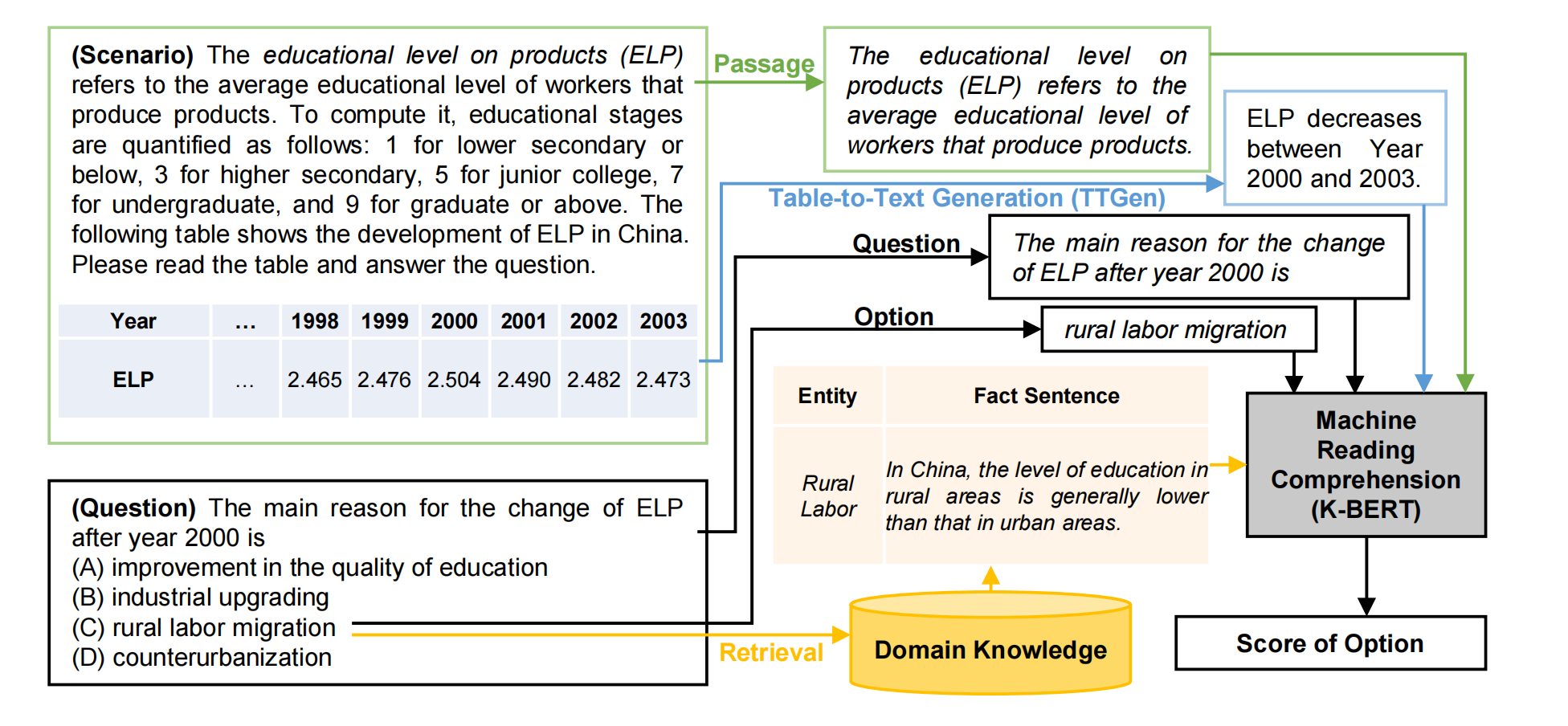
数据集构造
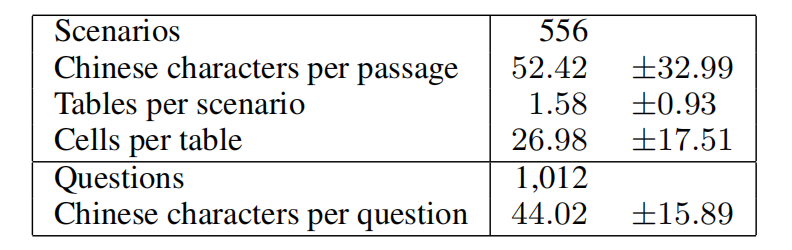
据我们所知,目前并没有针对于TSQA任务的数据集存在。因此,为了更好地完成研究任务,需要构造针对于此任务的数据集。
为了构造适合任务的数据集,我们从高中地理考试题中搜集题目。基于目前存在的GeoSQA数据集,我们收录了其中所有数据并重用构造数据集的代码,从网络上收集题目并扩充数据集。其中,对于图像文件是否描绘表格或其他类型的图表,需要采用识别手段。
为了解决上述问题,我们手动标记了200个正样本以及200个负样本,并训练了一个图像分类器以区分该图像是否适用于我们的数据集。对于分类器得出的假阳性样本,我们进行了手动剔除。
得到图像后,我们招募了15个本科生作为志愿者,利用OCR工具进行数据提取,并手动纠正OCR错误。对于非表格的图标,利用我们开发的工具手动提取数据。
随后,志愿者手动检查每个提取的表并去掉不规则表格。
最后,志愿者过滤掉数据集中不需要表格就可以回答的问题。
GeoTSQA达成了两个条件:1.所有问题均以表格为场景。 2.表格中蕴含解题所需的信息。
至此,数据集构造完毕。
MRC based on K-BERT
由于解决数据集中的问题需要利用地理领域的知识,我们采用了基于K-BERT的MRC方法。该语言模型可以利用外部知识进行阅读理解。
对于每一个选项
该式即可作为K-BERT的输入的一部分。
随后,我们使用K-BERT获取每个$I^{MRC}i
<h^{MRC}{i1},h^{MRC}{i2},…>=K-BERT(I^{MRC}{i},K)
$$
[CLS]token的向量化表示即被用作$I^{MRC}i
\omega_i=w^T_2\tanh(W_1h^{MRC}{i1}+b_1)+b_2
$$
损失函数:负对数似然函数,衡量二进制正确值与
K-BERT中使用的外部知识库K有两个来源:1. Clinga中的所有三元组 2.对Huang的语料库进行重用。
TTGen
我们需要将表格数据转换为文字描述以适应下游的MRC模型,故我们开发了TTGen来完成表格数据到文字的转换工作。
TTGen依赖于封装预定义操作表格数据的模板。这些模板可以执行复杂的操作以适应GeoTSQA中的复杂问题。我们将所有适应于表格的模板从中生成句子,并且为了适应K-BERT,我们对句子进行排序,并选择k个对解题最有用的句子。这样也能够过滤掉影响模型的噪声。
我们预定义了6个模板用于合成数字表格中的数据。
- 极值,描述某一行或某一列的最大/最小值。
- 特殊值,描述表格中元素和特殊值的大小或者相等关系。
- 与平均值比较,描述表格中某些元素的相对大小关系(如相对较大)。
- 单调性,描述表格中某些连续的元素值的增减变化情况。
- 趋势,从整体上描述表格某一行或某一列的变化趋势。
- 范围比较,描述表格中不同列或不同行之间的大小关系。
在利用模板生成句子后,我们需要将句子进行排序,以挑选对解题最有用的k个句子。
具体方法为:
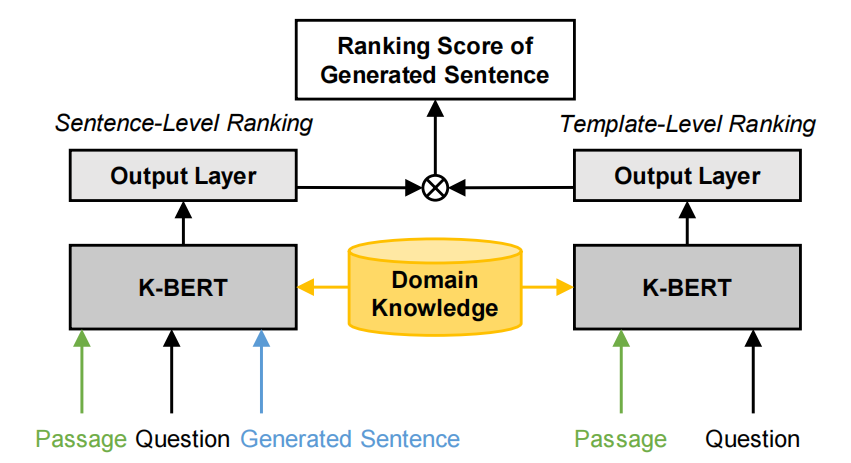
采用两个互补的排名模型进行打分,一个模型得出问题对句子的打分,另一个模型得出问题对句子模板的打分。
同样,这两个排名模型也利用K-BERT模型融合文字段落P、问题Q和外部知识K来完成文字到向量表示的转换,最后利用两层的全连接层再接softmax层的方式计算得到有用性得分
句子级表达式:
模板级表达式:
后续处理步骤与前文相同。
损失函数:负对数似然函数。
在分别得到句子得分和句子对应的模板得分后,将这两个得分相乘得到句子的最终得分。
整个处理过程如图:
实验部分
在TSQA任务上与各种基线模型进行了对比,同时也评估了句子排序模型。实验中主要对比由表格到文字的部分。
-
有监督方法:Field-Infusing、GPT-Linearization、Coarse-to-Fine、GPT-Linearization+、Coarse-to-Fine+
-
无监督方法:Linearization、Templation
-
黄金标准:Gold-Standard Sentence
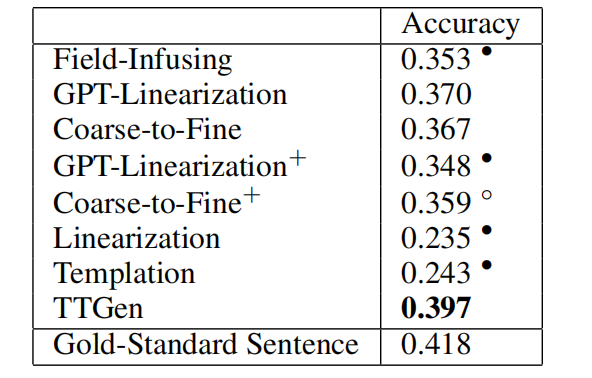
表2 TSQA的准确度对比
为了评估句子排序模型,我们测量了由模板生成的排名列表的质量,采用MAP与MRR作为评价指标。
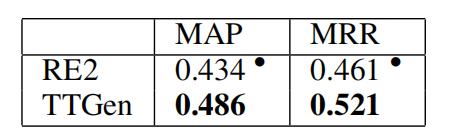
消融实验:为了分析表格和领域知识的作用,分别实现了两种TTGen的变体,一种忽略了表格数据,另一种忽略了领域知识。

主要贡献点
- 对最先进的MRC方法进行扩展,得到了名为TTGen的新型表格到文本的生成器。
- 构造且发布了第一个专门用于TSQA的数据集GeoTSQA。在该领域是开创性的工作。
研究过程中的难点及解决方案
难点:生成句子的排序
解决方案:
- 作为开创性的TSQA任务解决方案,TTGen中的核心为句子排序模型。该模型直接影响到后续模型的表现。故合理设计的句子排序模型至关重要。
- TTGen中的句子排序模型为了适用于GeoTSQA,采用了K-BERT模型作为解决方案,分两个级别出色地完成了句子有用性得分的计算并最终按照有用性得分排序。
有待进一步研究和解决的问题
- 句子排序模型的改进。与Gold-Standard Sentence所得出的结果相比,文中的句子排序模型仍有改进的空间。该排序模型的改进能够直接改良后续任务完成的效果。
- 如何使得MRC模型融合计算器和推理器以期获取更强大的推理能力以解决GeoTSQA中目前无法解决的问题。